 |
(1) |
that takes account of information about the inclusion of  — the spectrum of the operator
— the spectrum of the operator  — in a certain set
— in a certain set  , and uses the properties and parameters of those polynomials that deviate least from zero on
, and uses the properties and parameters of those polynomials that deviate least from zero on  and are equal to 1 at 0.
and are equal to 1 at 0.
 is a linear self-adjoint operator and
is a linear self-adjoint operator and  , where
, where  are the boundary points of the spectrum; then the Chebyshev iteration method uses the properties of the Chebyshev polynomials of the first kind,
are the boundary points of the spectrum; then the Chebyshev iteration method uses the properties of the Chebyshev polynomials of the first kind,  . For this case one considers two types of Chebyshev iteration methods:
. For this case one considers two types of Chebyshev iteration methods: |
(2) |
 |
(3) |
 |
in which for a given  one obtains a sequence
one obtains a sequence  as
as  . In (2) and (3)
. In (2) and (3)  and
and  are the numerical parameters of the method. If
are the numerical parameters of the method. If  , then the initial error
, then the initial error  and the error at the
and the error at the  -th iteration
-th iteration  are related by the formula
are related by the formula
 |
where
 |
(4) |
The polynomials  are calculated using the parameters of each of the methods (2), (3): for method(2)
are calculated using the parameters of each of the methods (2), (3): for method(2)
 |
(5) |
where  are the elements of the permutation
are the elements of the permutation  , while for method (3)they are calculated from the recurrence relations
, while for method (3)they are calculated from the recurrence relations
 |
(6) |
 |
Here
 |
 by choosing the parameters such that
by choosing the parameters such that  in (4) is the polynomial least deviating from zero on
in (4) is the polynomial least deviating from zero on  . It was proved in 1881 by P.L. Chebyshev that this is the polynomial
. It was proved in 1881 by P.L. Chebyshev that this is the polynomial |
(7) |
where  . Then
. Then
 |
(8) |
where
 |
 in
in  of the method
of the method  |
(9) |
where
 |
(10) |
 |
 and
and  by the formulas (9) and (10), one obtains the Chebyshev iteration method (3) for which
by the formulas (9) and (10), one obtains the Chebyshev iteration method (3) for which  is optimally small for each
is optimally small for each  .
. , the parameters
, the parameters  are chosen corresponding to the permutation
are chosen corresponding to the permutation  in formula (5) in such a way that (7) holds, that is,
in formula (5) in such a way that (7) holds, that is, |
(11) |
 |
Then after  iterations, inequality (8) holds for
iterations, inequality (8) holds for  .
.
 is the question of the stability of the method (2), (5), (11). An imprudent choice of
is the question of the stability of the method (2), (5), (11). An imprudent choice of  may lead to a catastrophic increase in
may lead to a catastrophic increase in  for some
for some  , to the loss of significant figures, or to an increase in the rounding-off errors allowed on intermediate iteration. There exist algorithms that mix the parameters in (11) and guarantee the stability of the calculations: for
, to the loss of significant figures, or to an increase in the rounding-off errors allowed on intermediate iteration. There exist algorithms that mix the parameters in (11) and guarantee the stability of the calculations: for  see Iteration algorithm; and for
see Iteration algorithm; and for  one of the algorithms for constructing
one of the algorithms for constructing  is as follows. Let
is as follows. Let  , and suppose that
, and suppose that  has been constructed, then
has been constructed, then |
(12) |
 |
 iterations in such a way that it is stable and such that it becomes optimal again for some sequence
iterations in such a way that it is stable and such that it becomes optimal again for some sequence  . For the case
. For the case  , it is clear from the formula
, it is clear from the formula |
(13) |
that  agrees with (11). If after
agrees with (11). If after  iterations one repeats the iteration (2), (5), (11) further, taking for
iterations one repeats the iteration (2), (5), (11) further, taking for  in (11) the
in (11) the  values
values
 |
(14) |
then once again one obtains a Chebyshev iteration method after  iterations. To ensure stability, the set(14) is decomposed into two sets: in the
iterations. To ensure stability, the set(14) is decomposed into two sets: in the  -th set,
-th set,  , one puts the
, one puts the  for which
for which  is a root of the
is a root of the  -th bracket in (13); within each of the subsets the
-th bracket in (13); within each of the subsets the  are permuted according to the permutation
are permuted according to the permutation  . For
. For  one substitutes elements of the first set in (5), (11), and for
one substitutes elements of the first set in (5), (11), and for  one uses the second subset; the permutation
one uses the second subset; the permutation  is defined in the same way. Continuing in an analogous way the process of forming parameters, one obtains an infinite sequence
is defined in the same way. Continuing in an analogous way the process of forming parameters, one obtains an infinite sequence  , uniformly distributed on
, uniformly distributed on  , called a
, called a  -sequence, for which the method (2) becomes optimal with
-sequence, for which the method (2) becomes optimal with  and
and
 |
(15) |
 |
 lies in a certain interval or within a certain domain of special shape (in particular, an ellipse); when information is known about the distribution of the initial error; or when the Chebyshev iteration method is combined with the method of conjugate gradients.
lies in a certain interval or within a certain domain of special shape (in particular, an ellipse); when information is known about the distribution of the initial error; or when the Chebyshev iteration method is combined with the method of conjugate gradients. |
and the application of the Chebyshev iteration method to this equation. The operator  is defined by taking account of two facts: 1) the algorithm for computing a quantity of the form
is defined by taking account of two facts: 1) the algorithm for computing a quantity of the form  should not be laborious; and 2)
should not be laborious; and 2)  should lie in a set that ensures the fast convergence of the Chebyshev iteration method.
should lie in a set that ensures the fast convergence of the Chebyshev iteration method.
References
| [1] | G.I. Marchuk, V.I. Lebedev, “Numerical methods in the theory of neutron transport” , Harwood (1986) (Translated from Russian) |
| [2] | N.S. Bakhvalov, “Numerical methods: analysis, algebra, ordinary differential equations” , MIR (1977) (Translated from Russian) |
| [3] | G.I. Marchuk, “Methods of numerical mathematics” , Springer (1982) (Translated from Russian) |
| [4] | A.A. Samarskii, “Theorie der Differenzverfahren” , Akad. Verlagsgesell. Geest u. Portig K.-D. (1984) (Translated from Russian) |
| [5a] | V.I. Lebedev, S.A. Finogenov, “The order of choices of the iteration parameters in the cyclic Chebyshev iteration method” Zh. Vychisl. Mat. i Mat. Fiz. , 11 : 2 (1971) pp. 425–438 (In Russian) |
| [5b] | V.I. Lebedev, S.A. Finogenov, “Solution of the problem of parameter ordering in Chebyshev iteration methods” Zh. Vychisl. Mat. i Mat. Fiz , 13 : 1 (1973) pp. 18–33 (In Russian) |
| [5c] | V.I. Lebedev, S.A. Finogenov, “The use of ordered Chebyshev parameters in iteration methods” Zh. Vychisl. Mat. i Mat. Fiz. , 16 : 4 (1976) pp. 895–907 (In Russian) |
| [6a] | V.I. Lebedev, “Iterative methods for solving operator equations with spectrum located on several segments” Zh. Vychisl. Mat. i Mat. Fiz. , 9 : 6 (1969) pp. 1247–1252 (In Russian) |
| [6b] | V.I. Lebedev, “Iteration methods for solving linear operator equations, and polynomials deviating least from zero” , Mathematical analysis and related problems in mathematics , Novosibirsk (1978) pp. 89–108 (In Russian) |
Comments
 of
of  with the zeros of (shifted) Chebyshev polynomials as done in (11), but (less sophisticatedly) sprinkled them uniformly over the interval
with the zeros of (shifted) Chebyshev polynomials as done in (11), but (less sophisticatedly) sprinkled them uniformly over the interval  . The use of Chebyshev polynomials seems to be proposed for the first time in [a1] and [a3].
. The use of Chebyshev polynomials seems to be proposed for the first time in [a1] and [a3]. , which immediately leads to the factorization
, which immediately leads to the factorization |
This formula has already been used in [a1] in the numerical determination of fundamental modes.
 (called “preconditioningpreconditioning” ), an often used “preconditionerpreconditioner” is the so-called SSOR matrix (Symmetric Successive Over-Relaxation matrix) proposed in [a8].
(called “preconditioningpreconditioning” ), an often used “preconditionerpreconditioner” is the so-called SSOR matrix (Symmetric Successive Over-Relaxation matrix) proposed in [a8]. is assumed to be real. An analysis of the case where the spectrum is not real can be found in [a5].
is assumed to be real. An analysis of the case where the spectrum is not real can be found in [a5]. on
on  . This leads to the theory of kernel polynomials introduced in [a9] and extended in [a11], Chapt. 5.
. This leads to the theory of kernel polynomials introduced in [a9] and extended in [a11], Chapt. 5. is tolerated; often other errors, e.g., truncation errors in discretized systems of partial differential equations, are more dominant.
is tolerated; often other errors, e.g., truncation errors in discretized systems of partial differential equations, are more dominant. is available, or in the non-self-adjoint case, it is often preferable to use the method of conjugate gradients (cf. Conjugate gradients, method of). Numerical algorithms based on the latter method combined with incomplete factorization have proven to be one of the most efficient ways to solve linear problems up to now (1987).
is available, or in the non-self-adjoint case, it is often preferable to use the method of conjugate gradients (cf. Conjugate gradients, method of). Numerical algorithms based on the latter method combined with incomplete factorization have proven to be one of the most efficient ways to solve linear problems up to now (1987).References
| [a1] | D.A. Flanders, G. Shortley, “Numerical determination of fundamental modes” J. Appl. Physics, 21 (1950) pp. 1326–1332 |
| [a2] | G.E. Forsythe, W.R. Wasow, “Finite difference methods for partial differential equations” , Wiley (1960) |
| [a3] | G.H. Golub, C.F. van Loan, “Matrix computations” , North Oxford Acad. (1983) |
| [a4] | G.H. Golub, R.S. Varga, “Chebyshev semi-iterative methods, successive over-relaxation methods and second-order Richardson iterative methods I, II” Num. Math. , 3 (1961) pp. 147–156; 157–168 |
| [a5] | T.A. Manteuffel, “The Tchebychev iteration for nonsymmetric linear systems” Num. Math. , 28 (1977) pp. 307–327 |
| [a6a] | L.F. Richardson, “The approximate arithmetical solution by finite differences of physical problems involving differential equations, with an application to the stresses in a masonry dam” Philos. Trans. Roy. Soc. London Ser. A , 210 (1910) pp. 307–357 |
| [a6b] | L.F. Richardson, “The approximate arithmetical solution by finite differences of physical problems involving differential equations, with an application to the stresses in a masonry dam” Proc. Roy. Soc. London Ser. A , 83 (1910) pp. 335–336 |
| [a7] | G. Shortley, “Use of Tchebycheff-polynomial operators in the numerical solution of boundary-value problems” J. Appl. Physics , 24 (1953) pp. 392–396 |
| [a8] | J.W. Sheldon, “On the numerical solution of elliptic difference equations” Math. Tables Aids Comp. , 9 (1955) pp. 101–112 |
| [a9] | E.L. Stiefel, “Kernel polynomials in linear algebra and their numerical applications” , Appl. Math. Ser. , 49 , Nat. Bur. Standards (1958) |
| [a10] | R.S. Varga, “Matrix iterative analysis” , Prentice-Hall (1962) |
| [a11] | E.L. Wachspress, “Iterative solution of elliptic systems, and applications to the neutron diffusion equations of nuclear physics” , Prentice-Hall (1966) |


 and
and  , we get the equality for the errors
, we get the equality for the errors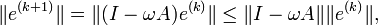
 the method convergences.
the method convergences.
 0.
0.
 ,
, 
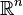 .
.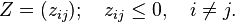





 orthogonal to
orthogonal to  . Thus
. Thus  (remove component in direction vi)
(remove component in direction vi) (normalize)
(normalize)