In two and three dimensions, rotation matrices are among the simplest algebraic descriptions of rotations, and are used extensively for computations in
geometry,
physics, and
computer graphics. Though most applications involve rotations in two or three dimensions, rotation matrices can be defined for
n-dimensional space.
Rotation matrices are always
square, with
real entries. Algebraically, a rotation matrix in
n-dimensions is a
n ×
n special orthogonal matrix, that is an
orthogonal matrix whose
determinant is 1:
The
set of all rotation matrices forms a
group, known as the
rotation group or the special
orthogonal group. It is a subset of the orthogonal group, which includes reflections and consists of all orthogonal matrices with determinant 1 or -1, and of the
special linear group, which includes all volume-preserving transformations and consists of matrices with determinant 1.
http://en.wikipedia.org/wiki/Rotation_matrix
As in two dimensions a matrix can be used to rotate a point (x, y, z) to a point (x′, y′, z′). The matrix used is a 3 × 3 matrix,
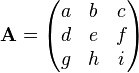
This is multiplied by a vector representing the point to give the result

Matrices are often used for doing transformations, especially when a large number of points are being transformed, as they are a direct representation of the
linear operator. Rotations represented in other ways are often converted to matrices before being used. They can be extended to represent rotations and transformations at the same time using
Homogeneous coordinates. Transformations in
this space are represented by 4 × 4 matrices, which are not rotation matrices but which have a 3 × 3 rotation matrix in the upper left corner.
The main disadvantage of matrices is that they are more expensive to calculate and do calculations with. Also in calculations where
numerical instability is a concern matrices can be more prone to it, so calculations to restore
orthonormality, which are expensive to do for matrices, need to be done more often.
 a non-empty, complete convex subset. Then, for all
a non-empty, complete convex subset. Then, for all  , there exists a unique best approximation a0 to x in A.
, there exists a unique best approximation a0 to x in A. . There exists a sequence (an) in Asuch that
. There exists a sequence (an) in Asuch that .
. .
. so
so .
. as
as 
 as
as  .
. ,
,  . Furthermore
. Furthermore as
as  ,
, .
.
 , which means
, which means  , thus completing the proof.
, thus completing the proof.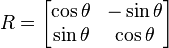
 .
.

 is the
is the 


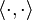 stands now for the standard
stands now for the standard  .
.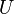 is an n by n matrix then the following are all equivalent conditions:
is an n by n matrix then the following are all equivalent conditions:
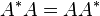

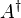 , then the Hermitian property can be written concisely as
, then the Hermitian property can be written concisely as