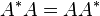Vector formulation
The law of cosines is equivalent to the formula

in the theory of vectors, which expresses the dot product of two vectors in terms of their respective lengths and the angle they enclose.

Fig. 10 — Vector triangle
Proof of equivalence. Referring to Figure 10, note that

and so we may calculate:

The law of cosines formulated in this notation states:

which is equivalent to the above formula from the theory of vectors.
-
(by definition of dot product)
If you think of the length of the 3 vectors |A|,|B| and |B-A| as the lengths of the sides of a triangle, you can apply the law of cosines here too (To visualize this, draw the 2 vectors A and B onto a graph, now the vector from A to B will be given by B-A. The triangle formed by these 3 vectors is applied to the law of cosines for a triangle)
In this case, we substitute: |B-A| for c, |A| for a, |B| for b
and we obtain: -
(by law of cosines)
Remember now, that Theta is the angle between the 2 vectors A, B.
Notice the common term |A||B|cos(Theta) in both equations. We now equate equation (1) and (2), and obtain
and hence
(by pythagorean length of a vector) and thus

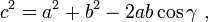



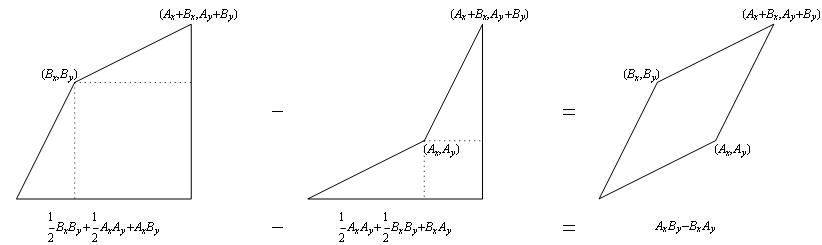
 a non-
a non- , there exists a unique
, there exists a unique  . There exists a
. There exists a  .
. .
. so
so .
. as
as 
 as
as  .
. ,
,  . Furthermore
. Furthermore as
as  ,
, .
.
 , which means
, which means  , thus completing the proof.
, thus completing the proof.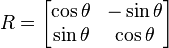
 .
.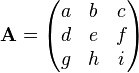

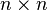

 is the
is the 

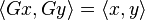

 stands now for the standard
stands now for the standard  .
. is an n by n matrix then the following are all equivalent conditions:
is an n by n matrix then the following are all equivalent conditions: