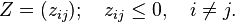a
P-matrix is a complex square matrix with every principal
minor > 0. A closely related class is that of
P0-matrices, which are the closure of the class of
P-matrices, with every principal minor

0.
Spectra of P-matrices
By a theorem of Kellogg, the eigenvalues of P– and P0– matrices are bounded away from a wedge about the negative real axis as follows:
- If {u1,…,un} are the eigenvalues of an n-dimensional P-matrix, then

- If {u1,…,un},
 , i = 1,…,n are the eigenvalues of an n-dimensional P0-matrix, then
, i = 1,…,n are the eigenvalues of an n-dimensional P0-matrix, then

Notes
The class of nonsingular
M-matrices is a subset of the class of
P-matrices. More precisely, all matrices that are both
P-matrices and
Z-matrices are nonsingular
M-matrices.
If the
Jacobian of a function is a
P-matrix, then the function is injective on any rectangular region of
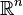
.
A related class of interest, particularly with reference to stability, is that of P( − )-matrices, sometimes also referred to as N − P-matrices. A matrix A is a P( − )-matrix if and only if ( − A) is a P-matrix (similarly for P0-matrices). Since σ(A) = − σ( − A), the eigenvalues of these matrices are bounded away from the positive real axis.
References
- R. B. Kellogg, On complex eigenvalues of M and P matrices, Numer. Math. 19:170-175 (1972)
- Li Fang, On the Spectra of P– and P0-Matrices, Linear Algebra and its Applications 119:1-25 (1989)
- D. Gale and H. Nikaido, The Jacobian matrix and global univalence of mappings, Math. Ann. 159:81-93 (1965)